AbiWord is know for its speed and its manageable size. But AbiWord also have some real bottlenecks in the PieceTable, that data structure used to store the text and everything. The PieceTable is a seriously obscure piece of software, and it suffer some design flaw, either internal, or external because of the framework we use (that have been developed along the years). These flaws have been investigated a little, but not really addressed.
So I'll start with a simple case: loading a RTF with a lot of tables. We know that this kind of document take some time to load and display, and that document will actually come from one of our bug reports. And I will use the command line text converter to just measure the loading and not have the layout engine being sollicited. That will come later.
The tools I will use to analyse are callgrind and KCachegrind. callgrind is valgrind tool that performs profiling a bit like gprof, but at run time, not requiring to rebuild with the -pg C compiler flag. KCachegrind is its companion application, part of KDE, that provides a graphical representation of the callgrind's output. It help visualising the profiling results.
I will rebuild AbiWord without debugging, because all the debugging messages just impact performance too much and will probably pollute the results, not counting the risk of asserts.
The first run is done this way:
$ callgrind abiword foo.rtf --too=foo.txt
I then open the callgrind.out.$! file in KCachegrind. I sort the list of function called on the "self" column, because what matters is the time spent in the function itself. We want to identify bottlenecks, and that is where they are. Sorting by "Incl." will just make the main() the top of the list. Here is what the list gives:
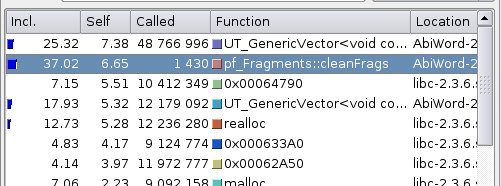
- is
UT_GenericVector<>::addItem()
- is
pf_Fragments::cleanFrags().
- is somewhere in the libc.
What shows up is that cleanFrags() accounts for 6.65% of the execution time and only 1,430 calls while addItem() has been for over 48,000 accounting for just 7.38% of the execution time. Let's measure that execution time. I'll do 3 rounds and only retain system and user time:
./src/wp/main/unix/AbiWord-2.6 --to=foo.txt 14.10s user 0.87s system 77% cpu 19.236 total
./src/wp/main/unix/AbiWord-2.6 --to=foo.txt 14.11s user 0.82s system 99% cpu 15.011 total
./src/wp/main/unix/AbiWord-2.6 --to=foo.txt 13.47s user 0.85s system 96% cpu 14.845 total
Note that 3 round is not statistically enoug, but I'll do approximations, that will be good enough.
Now let's look at the callee graph in KCachegrind:
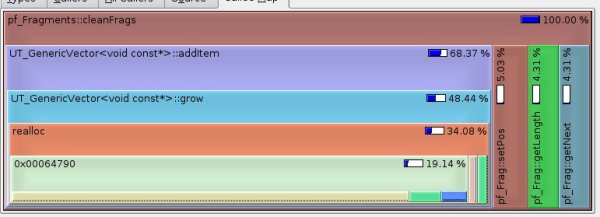
We see that most of the time is spent in UT_Vector::addItem() and mostly in UT_Vector::grow(). This last method reallocate the internal vector buffer to allow storing more items. That is a good clue. Maybe we should just size the vector better or something. So let's have a look at the source.
We see that we call UT_Vector::clear() and then re-add items into it. That is wrong. UT_Vector::clear() empty the vector. Most of the time we do that to add another bunch of items. Looking at the source of UT_Vector reveals that UT_Vector::clear() free the buffer, and we don't want to do that.
Here is the patch. Basically we just set the size of the vector to 0 and set the buffer to 0. This latest is needed because we assume that empty slots are set to 0. This is not an adequate design, but we have to deal with it.
And voila. First optimization. Here are the results:
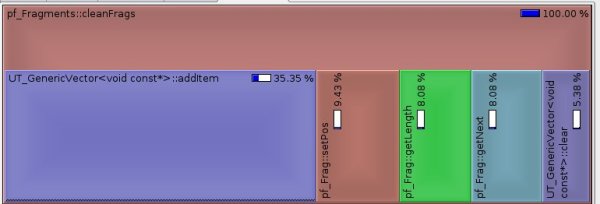
We just realize that UT_Vector::grow() no longer gets called. That is a lot of time saved. Unfortunately the callee list is not accurate as apparently I am having some issues when calling callgrind. With or without the patch I get an error that seems to interrupt callgrind. So I won't post it here.
Time measurement give this:
./src/wp/main/unix/AbiWord-2.6 --to=foo.txt 12.58s user 0.57s system 59% cpu 22.274 total
./src/wp/main/unix/AbiWord-2.6 --to=foo.txt 12.28s user 0.45s system 98% cpu 12.884 total
./src/wp/main/unix/AbiWord-2.6 --to=foo.txt 12.16s user 0.43s system 99% cpu 12.669 total
We saved a couple of seconds with that patch. Still pf_Fragments::cleanFrags() is still called too expensive, but I don't see what else could be done locally. I have to analyse what it does, why do we need it, and what can we do to avoid it.
